When Audio and Text Disagree: Revealing Text Bias in Large Audio-Language Models
Revealing and analyzing text bias in Large Audio-Language Models when audio and text inputs disagree.
Nov 1, 2025
Oedipus: LLM-enchanced Reasoning CAPTCHA Solver
An LLM-enhanced framework demonstrating vulnerabilities in reasoning-based CAPTCHA systems through AI-powered solving.
Oct 1, 2025
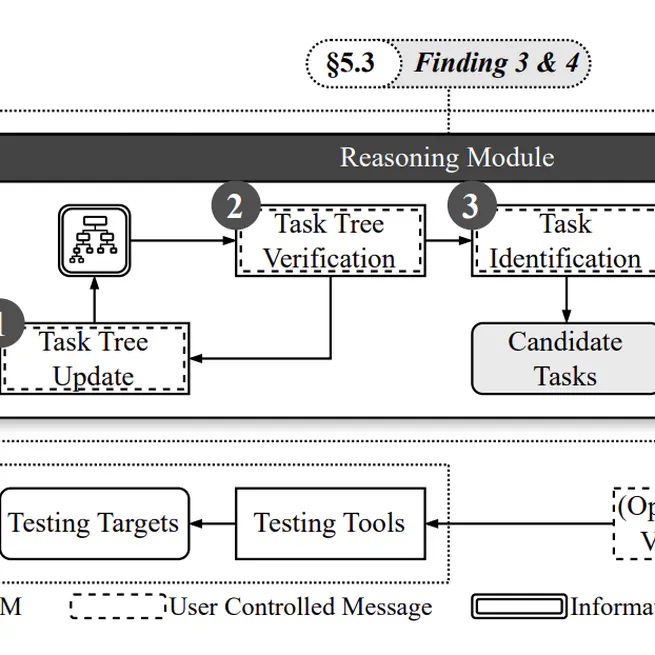
PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing
An LLM-empowered automated penetration testing framework that leverages domain knowledge inherent in LLMs, achieving 228.6% task completion improvement over baseline GPT models.
Aug 14, 2024
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
A comprehensive taxonomy and effective detection methods for glitch tokens in Large Language Models.
Jul 15, 2024
Source Code Summarization in the Era of Large Language Models
A comprehensive study of source code summarization capabilities with Large Language Models.
Jul 10, 2024
A Hitchhiker's Guide to Jailbreaking ChatGPT via Prompt Engineering
A comprehensive guide to jailbreaking ChatGPT via prompt engineering techniques.
Apr 20, 2024
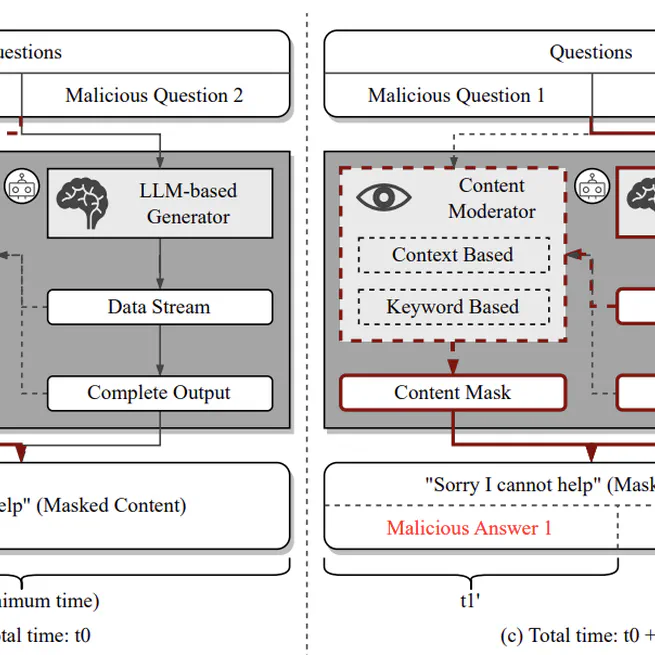
MASTERKEY: Automated Jailbreaking of Large Language Model Chatbots
A comprehensive framework for automated jailbreaking of Large Language Model chatbots, featuring novel attack methodologies and systematic analysis of defense mechanisms.
Feb 26, 2024
A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
A comprehensive analysis of jailbreak attack and defense techniques for Large Language Models.
Feb 20, 2024
PANDORA: Jailbreak GPTs by Retrieval Augmented Generation Poisoning
Novel attack framework exploiting RAG mechanisms to jailbreak LLMs through retrieval database poisoning. Distinguished Paper Award winner.
Feb 1, 2024
Digger: Detecting Copyright Content Mis-usage in Large Language Model Training
A novel approach to detecting copyright content mis-usage in Large Language Model training data.
Jan 1, 2024